Research Projects
- Multi-Network Representation Learning: Methods to learn representations for nodes in graphs have exploded in popularity as techniques from deep learning have been shown to be extensible to the network setting and have led to state-of-the-art results on single graphs. We show that most existing methods have weaknesses when applied to multiple graphs, because the criteria they optimize only make sense in a single graph. We develop a new method for representation learning, Structural Matrix Factorization that a) preserves node similarities based on structural identity that can be compared in multiple graphs, and b) omits the variance-inducing context sampling with random walks that many competing methods use. Our main framework, REGAL (REpresentation learning for Graph ALignment) iteratively alternates between learning alignment information by matching nodes with similar embeddings and learning embeddings that preserve similarities between nodes thought to align.

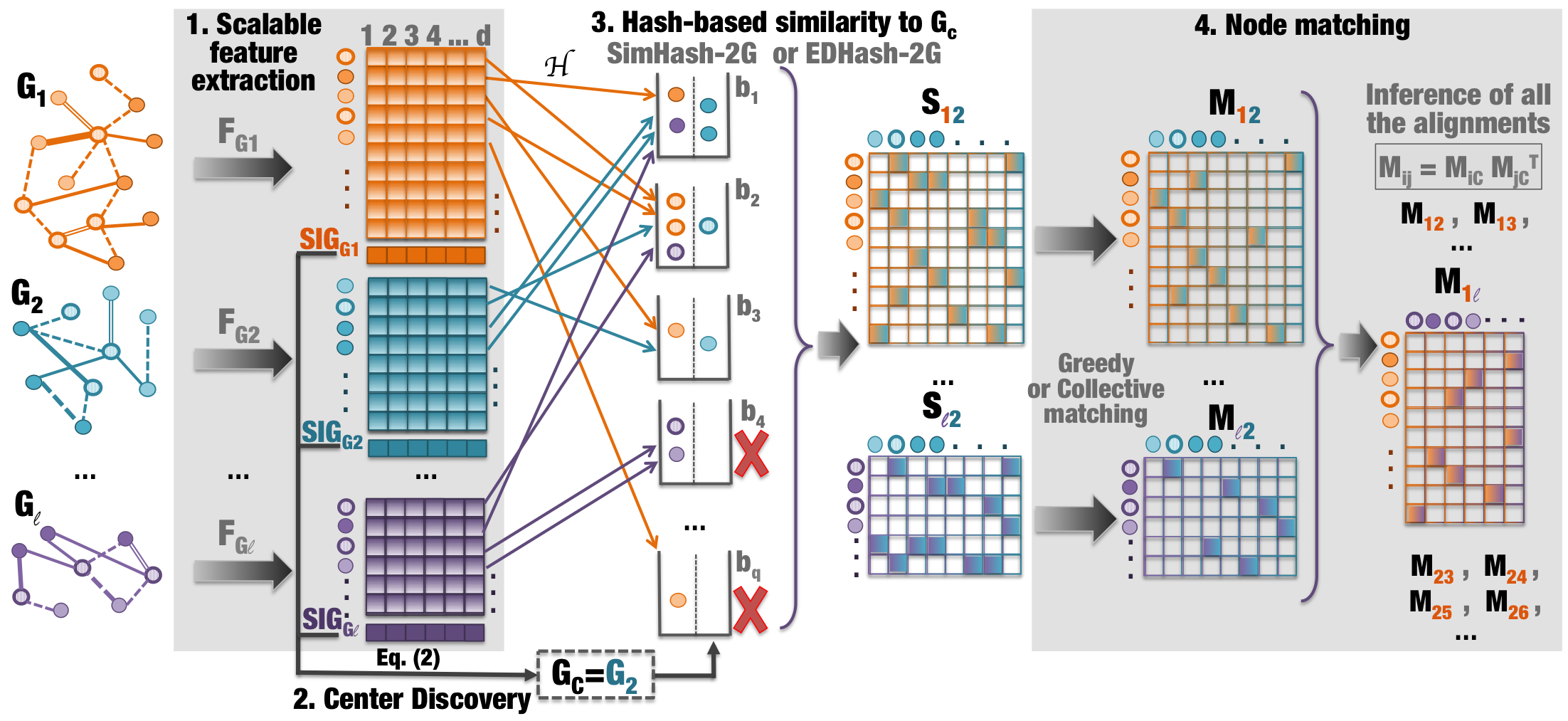
- Fast Network Alignment: We develop HashAlign, a flexible framework for aligning graphs quickly by using locality-sensitive hashing to avoid comparing all possible combinations of nodes. Instead, with high probability we only compare the most similar nodes based on feature vectors for which we propose sensible construction methods. This framework is flexible, as it can be easily extended to graphs where node and/or edge attributes are known; if known, they can be incorporated into the nodes' feature vectors.
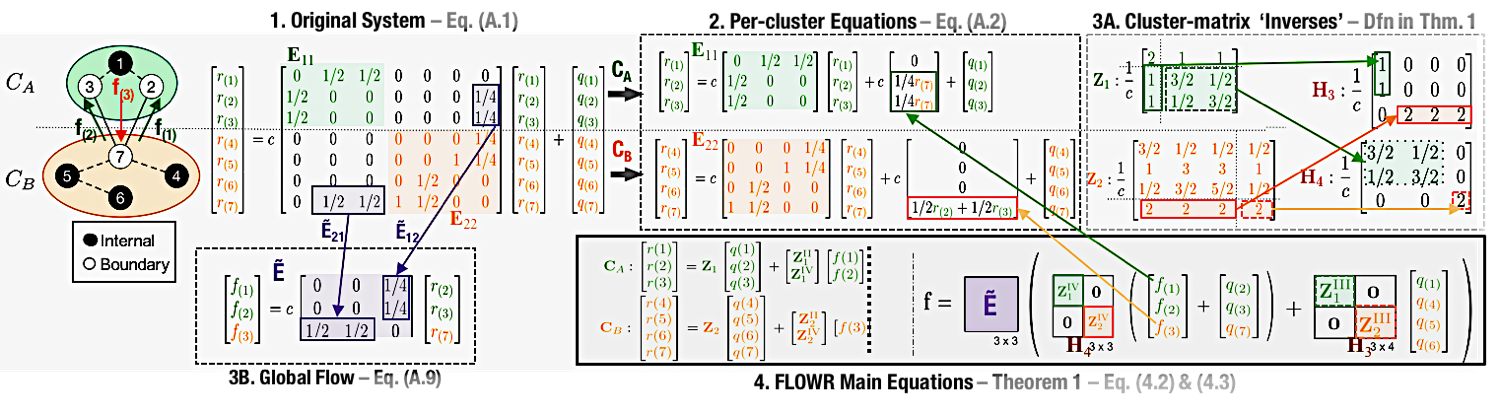
- Solving Large-Scale Linear Systems: We develop FLOWR, a fast "flow"-based methods for solving network problems that can be expressed as linear systems, including Random Walk with Restart (RWR), in a distributed setting. Such systems, we show, can be solved in a divide-and-conquer fashion by breaking them into subproblems (smaller clusters of the original network) such that the communication between subproblems (vertices adjacent to vertices in other clusters, or "flow") is minimized. Furthermore, our method can leverage the benefit of overlapping clusters, which makes individual clusters larger, but minimizes the amount of communication across clusters.
Publications
M. Heimann and D. Koutra. On generalizing neural node embedding methods to
multi-network problems. In Proceedings of the 13th International Workshop on
Mining and Learning with Graphs (MLG), 2017.